We're pivoting from browser agents
A quick explanation of our latest bet on AI data migration.

Vish Varma
Co-founder, CEO
Announcements

TL;DR
Web agents are now a commodity — many companies offer the same browser agent APIs.
Vertical SaaS companies routinely overestimate what agents can reliably do.
Public-facing agents live in a legal and technical grey zone.
General-purpose frameworks will increasingly struggle to differentiate on product + GTM
We’re doubling down on a specific workflow at Vern: AI data migration for implementation teams.
1) Web agents: commoditized, noisy market
There’s a big supply-side movement: dozens of startups and established products now expose browser-based agent APIs. The raw capability (open a page, click, read, extract) is table stakes - the market is rapidly becoming a catalog of similar offerings.
Implication: when everyone offers the same primitives, differentiation moves to reliability, speed, stealth, or ability to complete domain-specific workflows.
Here is a non-comprehensive list of web agent startups:
ChatGPT agent ($60bn) Conversational browser agent powered by ChatGPT
H Company ($220m) AI for QA and process automation
Browserbase ($68m) A web browser for your AI
TinyFish ($47m) The most deployed enterprise web agent
Sola ($21m) AI-native RPA
Browser-use ($17m) Automate repetitive online tasks
Yutori ($15m) Always-on AI that monitors the web for anything you care about
Airtop ($14m) Browser automation for AI agents
Reworkd ($4m) End-to-end data extraction
General agents (Undisclosed) Computer use agents
Steel (Undisclosed) OS Browser Infrastructure for AI Agents
Notte (YC-backed) The fast, reliable browser framework for AI Agents
Kaizen (YC-backed) Automate anything on the web
Simplex (YC-backed) Production-grade web agentsfor legacy portals
Hyperbrowser (YC-backed) Cloud Browsers for your AI Agents
CopyCat (YC-backed) Build Browser Automations With AI
Kernel (YC-backed) Core browser-agent infrastructure
ThirdLayer (YC-backed) Multi-layer browser intelligence
LaVague (YC-backed) Open-source framework for building Web Agents
Asteroid (YC-backed) AI Browser Workforce Powering Your Back-Office
Kura AI (YC-backed) Enterprise browser automation powered by AI
Skyvern (YC-backed) Automate Browser-Based Workflows with AI
CloudCruise (YC-backed) Ship browser agents like software
Parse bot (Went viral) Turn Any Website Into An API
Composite (Went viral) In-browser automation
Cua (YC-backed) Docker for computer use agents
Lightpanda (YC-backed) A new browser built for machines
2) Customers overestimate what agents can do
We’ve spent days trying to get an agent to consistently pick the right value from a dropdown. Small UI flakiness - dynamic DOMs, client-side rendering, timing issues, new captchas - makes many “simple” tasks brittle even for an agent running on the latest models.
Real world consequence: each new task (and often each new customer or site) requires bespoke extensions, prompts, or fallbacks.
Business consequence: unpredictability kills self-service. If we can’t predict success, we can’t confidently onboard customers.
Outlook: better models and tooling will help, but for now task creation UX and robust fallbacks are critical.
3) Public-facing agents are legally ambiguous
You’ll notice that no landing page above has an actual specific use case for customer success stories. During our conversations with other AI startups, we repeatedly hit the same legal friction: many sites prohibit automation in their terms of service. That’s intended to block abuse - but it also makes it risky when a customer asks you to act on their data.
Our stance: users should be able to authorize an agent to act on their behalf when they own or control the data.
Reality: platform TOS, rate limits, and partnership gatekeeping create real product and sales friction for web agent startups.
4) Product & GTM: the generalist trap
As infrastructure costs drop, two sustainable differentiation routes remain:
Frontier-model powered speed & reliability - expensive and defensible only if you win the performance arms race.
Business workflows - claim a specific pain point and own the end-to-end workflow for a specific business (non-technical) user.
We believe the second path is more tractable for us: pick a business workflow, prove ROI, and expand from there.
5) The defensive and commercial arms race at the edge
Cyber vendors and CDNs (Cloudflare, Vercel, etc.) are increasingly using ML protections to block bad actors automating browsers (see Kasada). At the same time, some companies like Tollbit are exploring ways to monetize controlled agent access.
Result: agents must navigate a shifting technical and commercial terrain.
Workaround arms race: frameworks are building stealth techniques; defenders are improving detection.
My take: The ability to authorize + whitelist web agents to act on your behalf on your own services will become table stakes for products
6) Our thesis and new focus
After synthesizing these challenges, we’ve narrowed our focus to a workflow with three virtues: narrow scope, high ROI, and defensibility.
Problem: SaaS implementation teams spend 2–8 weeks per mid-market customer migrating legacy data from their old system. Companies like Employment Hero, Deputy, Xero, Ofload, and several others (who we’ve spoken to) have explored several solutions to this problem:
Outsourced agencies: A random person in Manila copies and pastes your sensitive payroll information over to a CSV, remaps, then bulk uploads to Xero
In-house RDP: Implementation manager requests remote desktop access to customer computers, create a dump for them, then uploads it to new system
AI CSV importers: Tools like FlatFile and Dromo offer self-serve data remapping
But the reality is that none of these methods are scalable or truly white glove for non-technical customers. Globally its billions in delayed revenue recognition, expensive headcount, and unhappy mid-market / enterprise customers.
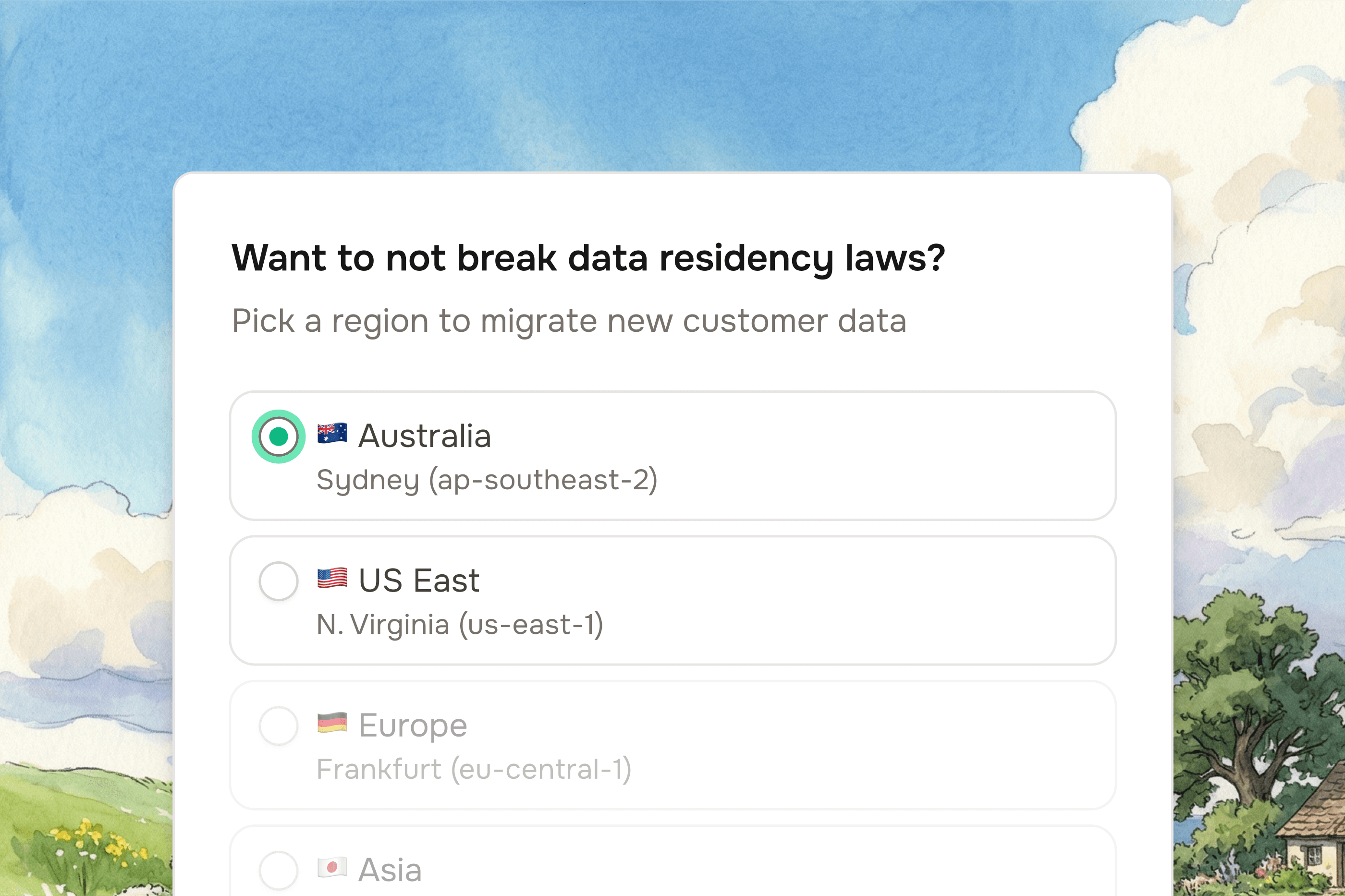
Opportunity: automate the data extraction, cleaning, and transformation work where agent reliability, consent, and legal risk are fully auditable - and where the dollar value per customer is large. Systems of record with compliance mandates for data retention are ideal targets - think migration of tax-related (HR, payroll), legal, healthcare, and logistics data.
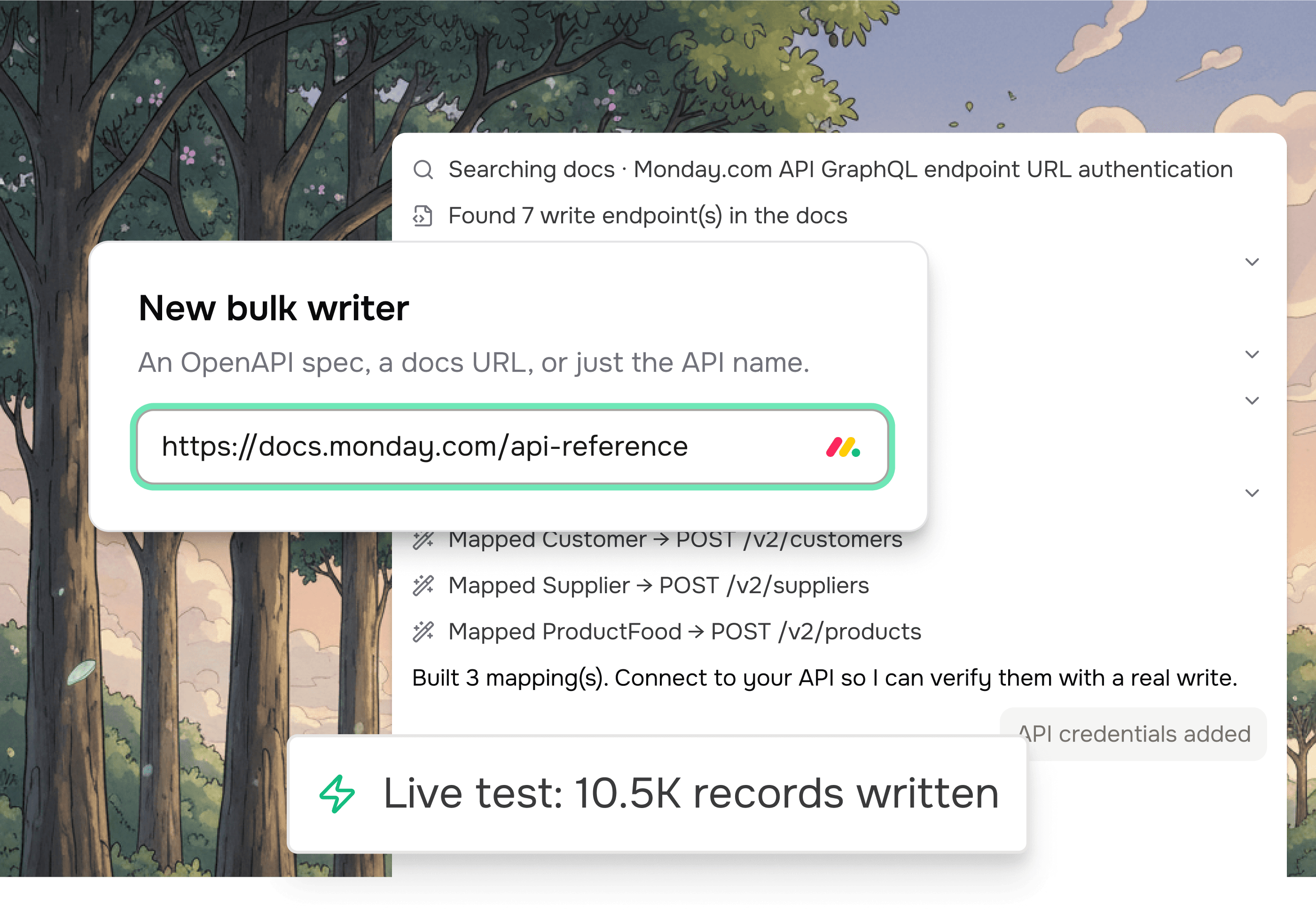
Our product wedge: AI-driven data collection + transformation for implementation teams. A blend of computer using and API agents that scrape, ingest, clean and convert customers’ legacy data and files into ready-to-upload bulk formats.
Why HR implementations first? I spent nearly two years building complex payroll-related product at Employment Hero and understand the workflow; Roupen brings a stack of ML + data expertise from Suncorp.
10 onboardings per month, each delayed 4 weeks by data collection, costs $250,000/year in missed revenue, employee time, and poor CX.
Closing
The web agent layer is powerful - but it’s noisy and brittle for broad, public-facing automation. We’re placing our bets on solving an expensive, internal workflow and hope to build defensible expertise there.